Prompt Engineering
也成为In-Context Prompting, 是指在不更新模型权重的情况下如何与大模型交互以引导其行为以获得所需结果的方法。人工智能领域,Prompt指的是用户给大语言模型发出的指令。
提示词技巧:
- 详细的描述
- 让模型充当某个角色
- 使用分隔符标明输入的不同部分
– 例:用20个字符总结由三引号分割的文本。“”“在此插入文本”“” - 对任务指定步骤:对于可以拆分的任务可以尽量拆开,最好能为其指定一系列步骤
– 步骤1:“”“用户输入文本”“”,用一句话总结这段文本,并加上前缀“Summary”
– 步骤2:将步骤1中的摘要翻译成英语,并添加前缀“翻译: ” - 提供例子:本质类似于few-shot learning。先扔给大模型举例,然后让模型按照例子来输出
– 按照这句评论文本的格式:““”用户输入文本”“”,帮我创造新的样本 - 基于文本文档:帮助大模型问答,**降低模型“幻觉”**, 经典知识库用法,让大模型使用我们提供的信息来组成答案:- 根据下文中三重引号引起来的文章来回答问题。如果在文章中找不到答案,请写“我找不到答案”, 不要自己造答案。“”“<在此插入文档>”“”“”“<在此插入文档>”“”问题:<在此插入问题>
大模型本身是一种很简单的结构:用户输入,模型输出。不管RAG还是Agent智能体或其他围绕模型的各种复杂的开发工作,本质上都可以简单总结为在提示词上下功夫。
Few-Shot, Zero-Shot思想
Zero-shot Learning(联想),指在训练阶段不存在与测试阶段完全相同的类别,但是模型可以使用训练过的知识来推广到测试集中的新类别上。“零样本”学习。因为模型在训练时从未见过测试集中的新类别,在模型训练和提示词优化中均有体现。
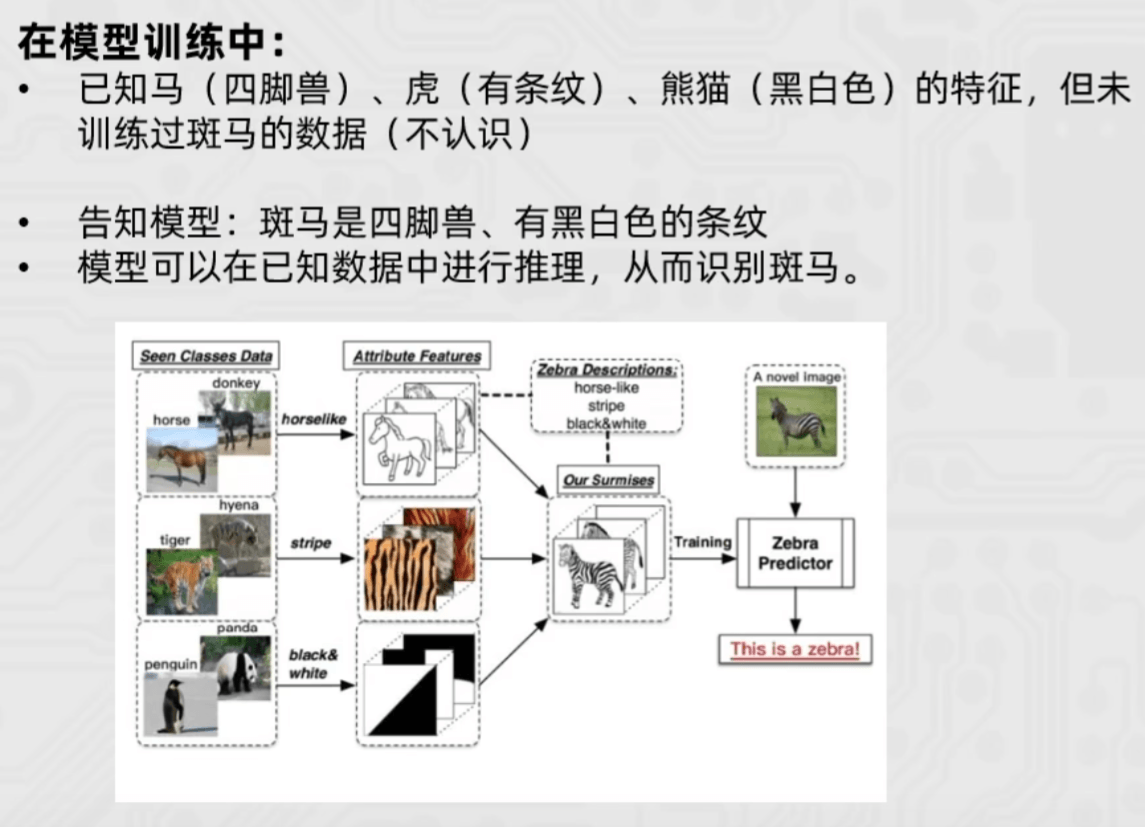
在提示词优化中:用于基于已训练的能力,不提供任何示例,仅通过语言去描述任务的要求、目标和约束,让模型直接生成结果。简单来说就是“用语言定义任务,解放(信任)模型的预训练知识”。
例:请判断“”包围的用户评论中的情感倾向,输出 正面 或 负面。“这款代餐鸡胸肉饱腹感很强,吃起来也不柴,很推荐!”
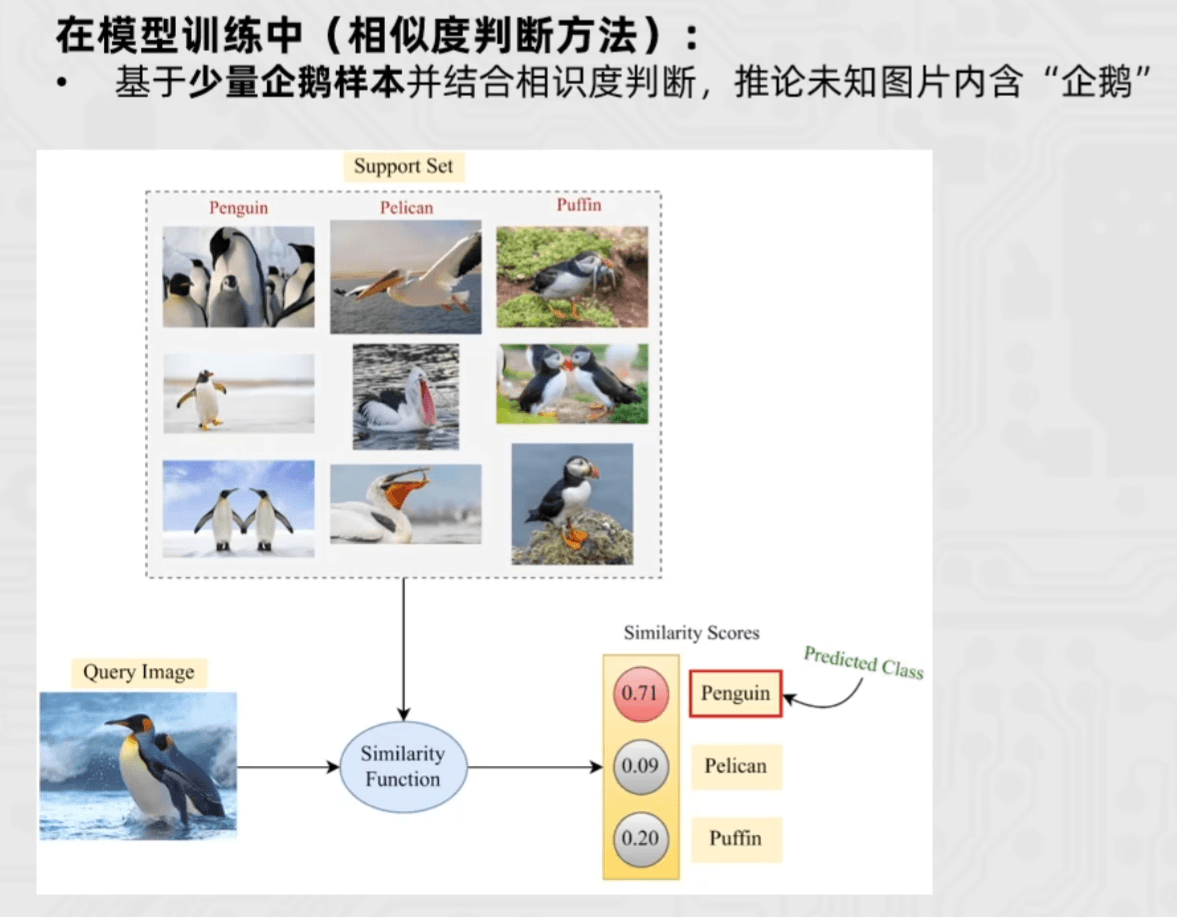
Few-shot Learning (示例)是指少样本学习,当模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,对应的有one-shot learning,单样本学习,也算样本少到为一的情况下的一种few-shot learning
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", #阿里云百炼
)
completion = client.chat.completions.create(
model="qwen-max",
messages=[
{"role": "system", "content": "你是一位AI助理"},
{"role": "assistant", "content": "请判断“”包围的用户评论中的情感倾向,输出 正面 或 负面"},
{"role": "user", "content": "这款代餐鸡胸肉饱腹感很强,吃起来也不柴,很推荐!"},
{
"role": "assistant",
"content": '''请抽取产品名称和核心卖点2个字段,格式为Json,我提供2个示例。
示例1:MacBookPro高效节能,性能强大,适合牛马工作使用
输出:{"产品名称": "MacBookPro", "核心卖点": "高效节能,性能强大,适合牛马,适合办公"}
示例2:华为Mate60Pro拍照效果非常好,续航能力强,适合喜欢拍照的用户
输出:{"产品名称": "华为Mate60Pro", "核心卖点":"续航强,拍照好"}'''
},
{"role": "user", "content": "这只火鸡真聪明,它会用AI技术来分析用户评论的情感倾向,并且能够抽取出产品的名称和核心卖点,真是太棒了!"}
],
#stream = True #流式输出
)
print(completion.choices[0].message.content)
金融信息分类样例:
from openai import OpenAI
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
examples_data = { # 示例数据
'新闻报道': '今日,股市经历了一轮震荡,受到宏观经济数据和全球贸易紧张局势的影响。投资者密切关注美联储可能的政策调整,以适应市场的不确定性。',
'财务报告': '本公司年度财务报告显示,去年公司实现了稳步增长的盈利,同时资产负债表呈现强劲的状况。经济环境的稳定和管理层的有效战略执行为公司的健康发展奠定了基础。',
'公司公告': '本公司高兴地宣布成功完成最新一轮并购交易,收购了一家在人工智能领域领先的公司。这一战略举措将有助于扩大我们的业务领域,提高市场竞争力',
'分析师报告': '最新的行业分析报告指出,科技公司的创新将成为未来增长的主要推动力。云计算、人工智能和数字化转型被认为是引领行业发展的关键因素,投资者应关注这些趋势'
}
# 分类列表
examples_types = ['新闻报道', '财务报道', '公司公告', '分析师报告']
# 提问数据
questions = [
"今日,央行发布公告宣布降低利率,以刺激经济增长。这一降息举措将影响贷款利率,并在未来几个季度内对金融市场产生影响。",
"ABC公司今日发布公告称,已成功完成对XYZ公司股权的收购交易。本次交易是ABC公司在扩大业务范围、加强市场竞争力方面的重要举措。据悉,此次收购将进一步巩固ABC公司在行业中的地位,并为未来业务发展提供更广阔的发展空间。详情请见公司官方网站公告栏",
"公司资产负债表显示,公司偿债能力强劲,现金流充足,为未来投资和扩张提供了坚实的财务基础。",
"最新的分析报告指出,可再生能源行业预计将在未来几年经历持续增长,投资者应该关注这一领域的投资机会",
"小明喜欢小新哟"
]
messages = [
{"role": "system", "content": "你是金融专家,将文本分类为['新闻报道', '财务报道', '公司公告', '分析师报告'],下面有示例:"},
]
for key, value in examples_data.items():
messages.append({"role": "user", "content": value})
messages.append({"role": "assistant", "content": key})
for question in questions:
response = client.chat.completions.create(
model="qwen3-max",
messages=messages + [{"role": "user", "content": f"按照示例,回答这段文本的分类类别:{question}"}],
)
print(response.choices[0].message.content)