是什么时候喜欢上听播客的呢?来德国之后吧,确切的说应该是15年正式入学后。个人的感触是,在德国最难熬的并不是无尽的学业问题,而是从早晨睁开眼到晚上要和自己说晚安了,都没有和几个人有过交流。来这里感觉最得到锻炼的就是忍受长时间的孤单。有个男女朋友还好,心灵的伴侣到不清楚,至少生活的依靠是很给人以安慰的。
更加感觉到这个世界对于单身狗满满的恶意。
有点跑题。
一个人生活,一个人学习,一个人住的话整个屋会特别的安静,不用担心有人吵到你。可是这种环境太让人压抑了。一些感觉难以描述,只有经历过才会有共鸣。
当时为了让家里有点生活气息,就找点节目随便播播,也不为听内容,就是让家里不那么的冷清。当时听过很多电台,新闻酸菜馆也是随便放放,可是听了几期后觉得有点意思,后来就每期必听,真的成了一条酸菜鱼。
遗憾的是,今年的10月,本来说相伴永远的公开节目停播了,其实之前也有想到,可是真的到了这个时候还是感觉好不舍。太多压抑的夜晚,是叮叮和王掌柜陪我度过的。可以说,这档节目对于我的留学这几年有特别重要的意义,不想说再见。
还好有会员节目,可是我是一个穷逼,一直买不起。。。公开节目停播后,我凑了微信余额宝以及银行卡三个地方的钱,终于凑齐了会员费,开始成为一名VIP酸菜鱼。订阅后发现一个问题,最新的节目可以通过iPhone的博客来很方便的播放,而往期节目需要到官方网站上点播,或者从网站下载播放。这也太不方便了。
看了下官网当时有102期会员节目,一个一个点击下载需要至少半个小时,太浪费时间了。所以我想着写个爬虫自动下载这一百多个音频。
好讽刺的是,写爬虫至最终能用用了我两个多小时。。。
很简单的一个python爬虫,我拿到这里提供给同样需要这个工具的同学。注意,爬虫需要vip会员账号登陆网站后的验证信息,所以用这个爬虫知识给购买了会员需要下载全集的同学一个方便,并不能在未购买的情况话来获得资源。
#coding: utf-8
import urllib.request
import re
header = { 'Host': 'vip.wasai.org',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Referer': 'http://vip.wasai.org/wp-login.php',
# 'Accept-Encoding': 'gzip, deflate', 支持压缩后,收到的是gzip后的数据流,还需要解压,增加工作量,故将此特性去掉。
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,de;q=0.4,zh-TW;q=0.2',
'Cookie': '最重要的一项: 这里粘贴你的cookie'
}
def getHtml(url):
req = urllib.request.Request(url, headers=header)
page = urllib.request.urlopen(req)
html = page.read()
html = html.decode('utf-8')
return html
def getVIP(html):
reg = r'<a href="(.*\.mp3)">.*\.mp3</a></audio>'
VIPlist = re.findall(reg, html)
return VIPlist
if ( __name__ == "__main__" ):
global total
total = 0
for page in range(32):
url = "http://vip.wasai.org/page/"+str(page)+"/"
htmlsource = getHtml(url)
VIPlist = getVIP(htmlsource)
for VIPurl in VIPlist:
name = re.findall('.*/(.*\.mp3)',VIPurl)
print ("downloading file %i: %s" %(total, name[0]))
urllib.request.urlretrieve(VIPurl, './%s' %name[0])
total += 1
print("Download all files Scuess!")
使用方法很简单:
- 首先默认读者有python基础能力,能够简单编写hallo world就够了。选择一款python编译器,我用的是PyCharm,我相信其他编辑器也可以的,我本地用的是python3.5,理论上3以上版本应该都可用。
- 首先用chrome打开新闻酸菜馆VIP官方页面:http://vip.wasai.org, 右上角有登陆,用你的VIP账号登陆。
- 登陆后会员节目就会有播放条以及下载链接,此时可以一个一个手动点击下载,可是太慢了,这个就是懒惰的结果,让电脑自动下载。
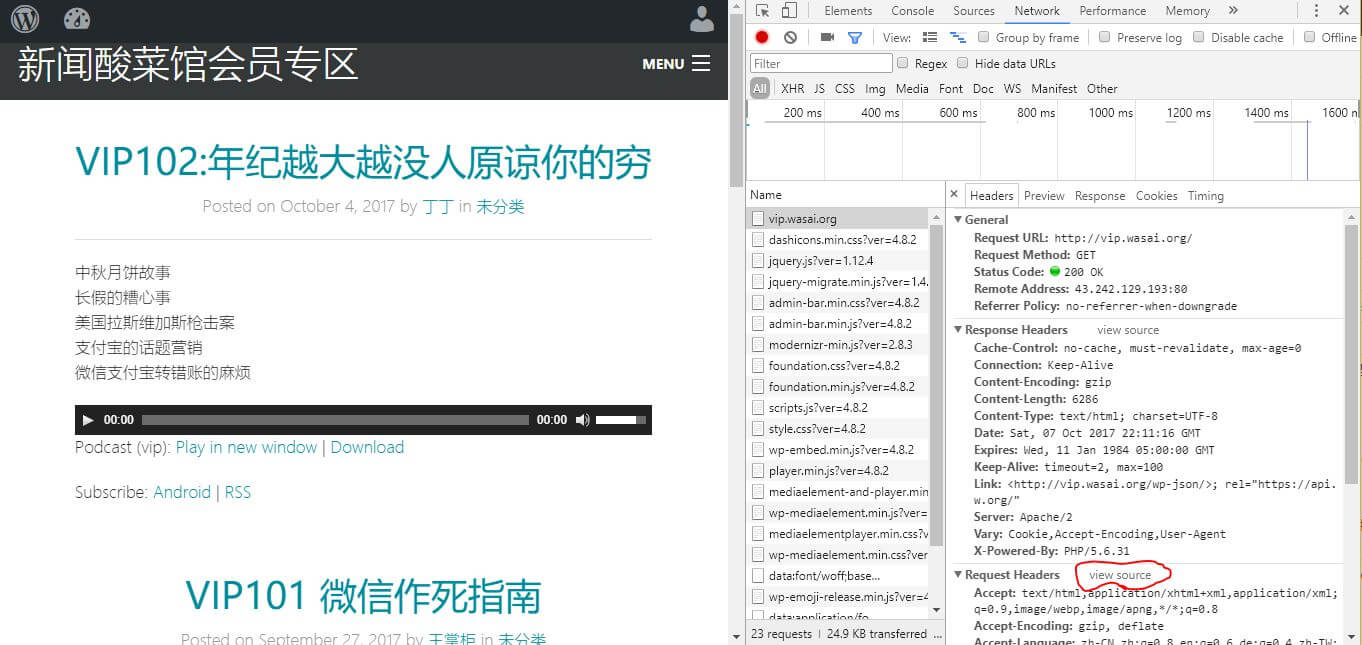
- 打开chrome开发者工具(设置-更多工具-开发者工具),弹出一个页面,切换到页面里便network栏,这里记录网页通讯的信息。然后刷新一下新闻酸菜馆网页(F5)。

- 类似这样的页面,然后点击Request Headers 右边的view source,把里边cookie一项的内容复制到代码中cookie那一栏中。一定注意不要多复制空格,以及在python代码中,放在两个单括号中。
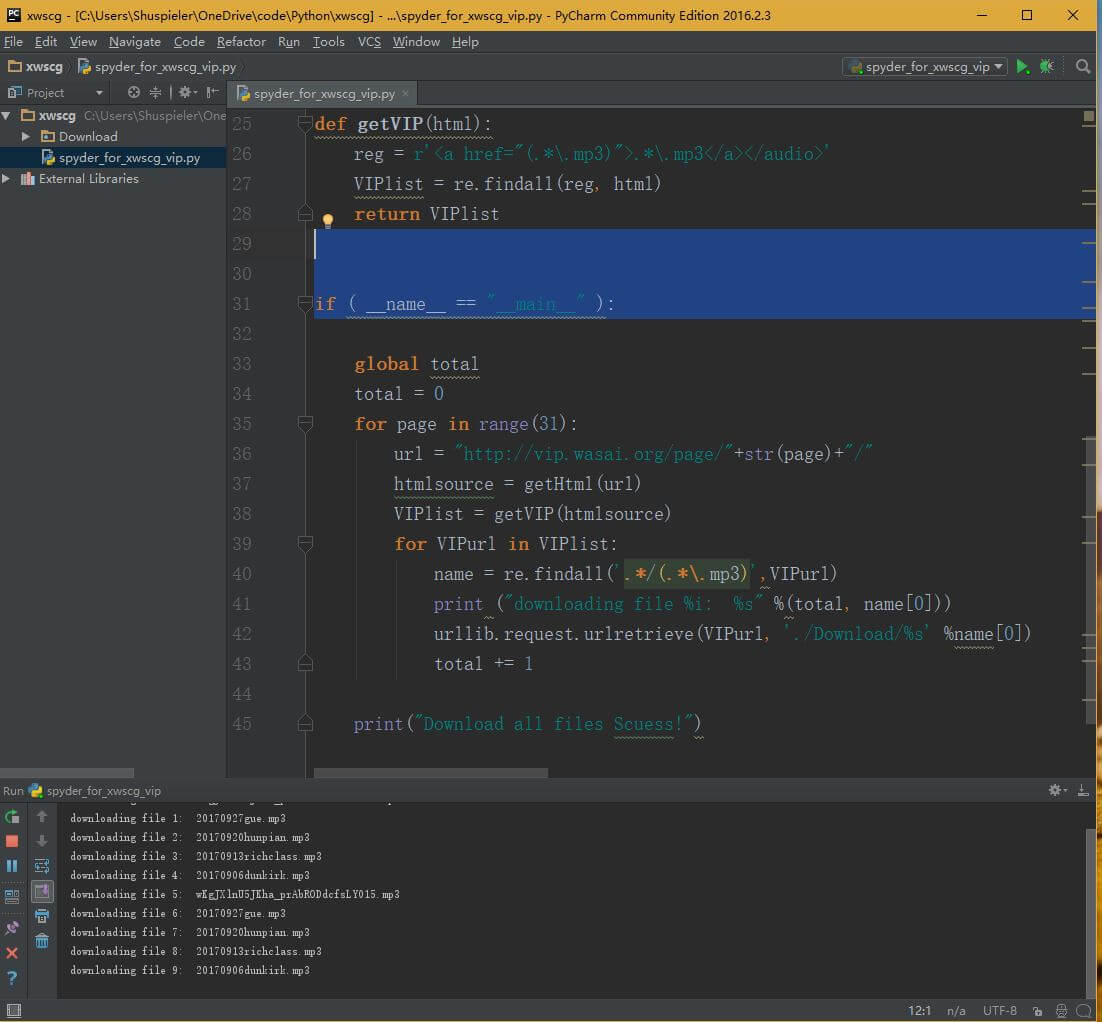
- 一切顺利的话,点击运行就开始下载了。大约需要一段时间全部下载完成,在交互框中可以看到正在下载第几个音频文件。

- 这是我下载时候的截图。
- 全部下载完成后,音频文件就会存在和python文件相同的文件夹。

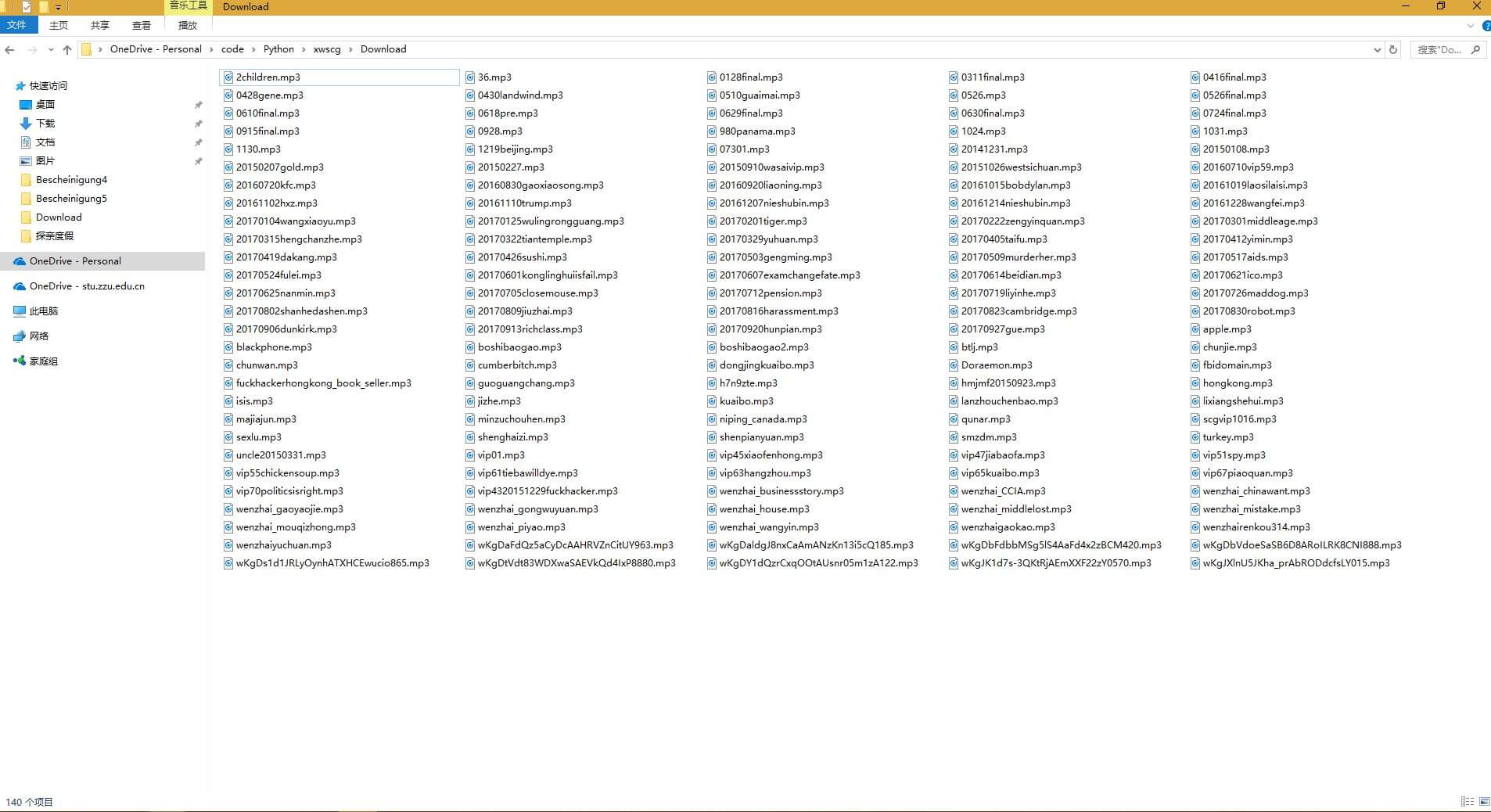
比较有意思一点是,一共102期会员节目,我竟然下载到140个音频文件,理论上是不会下载到重复文件的,难道是我找到了隐藏节目吗?
支持叮叮和王掌柜,支持新闻酸菜馆播客,放出爬虫工具,至于我下载到的音频文件我当然不能够分享了。谢谢各位看官,致敬。
同在用python
开发比较高效
你好,按照你的方法做,嘿嘿~粘到Cookie这一项的时候就手忙脚乱了,比如我的Cookie是这样写的,请问我应该从哪里粘到python才能正常运行,请指教:
Cookie:wordpress_test_cookie=WP+Cookie+check; wordpress_logged_in_bc97f5351e29d2b24f0e179b2caa37bf=levis%7C1535215476%7C2QwwKMQCQScJi0tFOlWISPFDhtvBZ4mQ9DFlonoKe30%7C78be4f625df806246750105c6323abd5ce20c54f5b9c030c27b4812709219361
就是将cookie 冒号后边的内容,整体复制粘贴到代码cookie后边,替换掉我写的中文字那里,另外现在会员节目比之前多了,可能总页数32需要改成现在的页数。
另外提醒一下就是我为了回复你消息让你能看到,所以也得把你的留言放出来,这样不好的一点是所有人都能看到你的cookie,你最好在网站上登出一下这样这个cookie就失效了。
您好谢谢您愿意分享,但是按照上述方法,显示报错,原因如下,麻烦问下您种情况怎么解决呢?谢谢
Traceback (most recent call last):
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 1318, in do_open
encode_chunked=req.has_header(‘Transfer-encoding’))
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py”, line 1239, in request
self._send_request(method, url, body, headers, encode_chunked)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py”, line 1285, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py”, line 1234, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py”, line 1026, in _send_output
self.send(msg)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py”, line 964, in send
self.connect()
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/http/client.py”, line 1400, in connect
server_hostname=server_hostname)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ssl.py”, line 407, in wrap_socket
_context=self, _session=session)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ssl.py”, line 814, in __init__
self.do_handshake()
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ssl.py”, line 1068, in do_handshake
self._sslobj.do_handshake()
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/ssl.py”, line 689, in do_handshake
self._sslobj.do_handshake()
ssl.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:833)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “/Users/AlexYan/Downloads/download/spyder_for_xwcsg_vip.py”, line 40, in
htmlsource = getHtml(url)
File “/Users/AlexYan/Downloads/download/spyder_for_xwcsg_vip.py”, line 22, in getHtml
page = urllib.request.urlopen(req)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 223, in urlopen
return opener.open(url, data, timeout)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 532, in open
response = meth(req, response)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 642, in http_response
‘http’, request, response, code, msg, hdrs)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 564, in error
result = self._call_chain(*args)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 504, in _call_chain
result = func(*args)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 756, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 526, in open
response = self._open(req, data)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 544, in _open
‘_open’, req)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 504, in _call_chain
result = func(*args)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 1361, in https_open
context=self._context, check_hostname=self._check_hostname)
File “/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/urllib/request.py”, line 1320, in do_open
raise URLError(err)
urllib.error.URLError:
sorry现在才回复你。应为这个脚本是一年多前写的,期间可能python也升级了,网站也升级了,所以可能就出现你现在这种报错得情况。我觉得你既然能够运行到这一步,应该已经有了基本的python功底,你可以以照着我的模板重新写一个新的程序,我相信以你得基础再加上参考应该可以实现的。你有了新的脚本后可以发表在你的博客或者其他公共空间上,然后给我留言我可以给你在文章中标注链接,为你引流~~
旧节目可以抓取下载链接,然后写成rss文件,这样就可以在泛用型播客客户端听旧节目了,比你这个方法收听方便。我
这个也是解决办法之一,不过就是对播放器有要求了。
因为有一些不是讨论新闻的音频,比如「会员文摘」